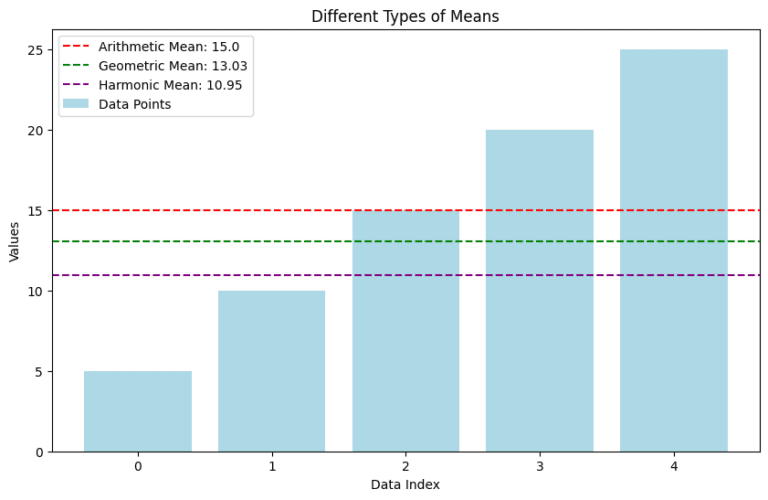
- Data Points (Light Blue Bars): These bars represent the individual values in the dataset: [5, 10, 15, 20, 25].
- Arithmetic Mean (Red Dashed Line): This line indicates the arithmetic mean of the dataset. It’s calculated as the sum of all values divided by the number of values.
- Geometric Mean (Green Dashed Line): This line shows the geometric mean, which is particularly useful for datasets that involve rates and ratios.
- Harmonic Mean (Purple Dashed Line): The harmonic mean is depicted here, ideal for datasets with rates, such as speeds.
The graph visually demonstrates how each type of mean provides a different perspective on the central tendency of the data, highlighting the importance of choosing the right mean for your specific data analysis needs.
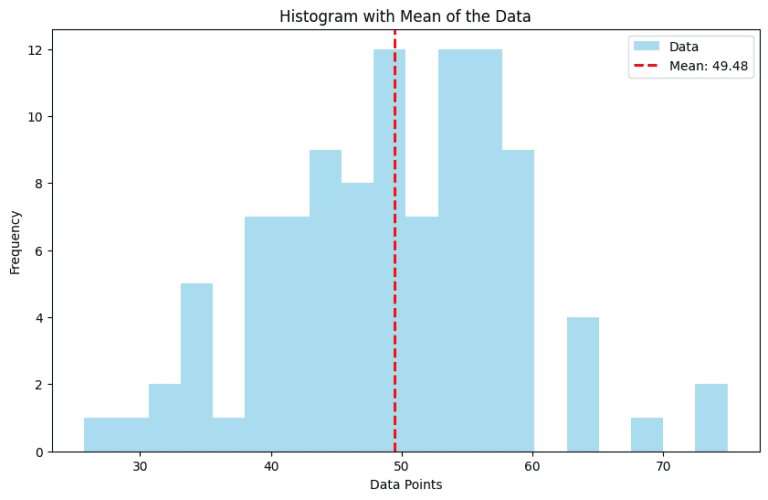
The Mean in Visual Representation 📊
In graphical terms, the mean can be depicted as a line across a bar chart or a dot on a line graph, representing the average value across the dataset.