import matplotlib.pyplot as plt
import numpy as np
# Example data
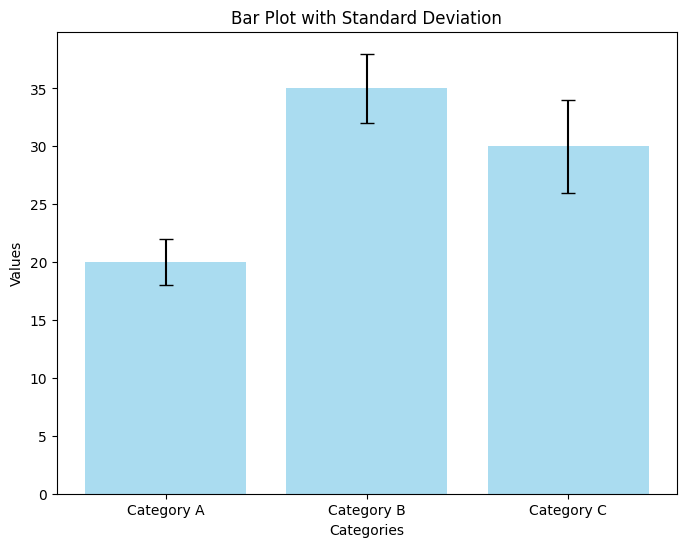
categories = ['Category A', 'Category B', 'Category C']
values = [20, 35, 30]
std_devs = [2, 3, 4]
# Creating the bar plot
plt.figure(figsize=(8, 6))
bar_positions = np.arange(len(categories))
plt.bar(bar_positions, values, yerr=std_devs, capsize=5, color='skyblue', alpha=0.7)
# Adding labels and title
plt.xlabel('Categories')
plt.ylabel('Values')
plt.xticks(bar_positions, categories)
plt.title('Bar Plot with Standard Deviation')
# Show the plot
plt.show()